How I do Machine Learning
Introduction
In my experience, most machine learning engineers spend far too much time on modeling and not nearly enough on eval sets and the underlying training data. This post is about the workflow I've built up over the last ~10 years to push against that tendency. It has been heavily shaped by my time with Andrew Ng at both Stanford and LandingAI, where I worked on machine vision problems related to manufacturing, and many of the ideas are borrowed from Andrew Ng's book Machine Learning Yearning, which I encourage you to read as well. That said, I think these techniques generalize well beyond manufacturing and can help anyone doing applied machine learning.
Eval Sets
Before I start any machine learning project, the first thing I do is develop my eval sets. They don't need to be large to start. Even a small eval set of ~10 to 20 examples can be helpful. What matters most is that you are collecting real data from real customer problems.
The best way to get this data is to talk directly with a customer, or if that isn't possible, with a product manager who deeply understands the customer problem. It is super important that you obtain this data firsthand rather than relying on existing open source data or synthetic data. You want to be working on problems that are as close as possible to the real customer problems.
It's also important to remember that eval sets are living things. You will add new eval data as you uncover new problems, you will delete eval data as it becomes irrelevant, and you will change labeling schemes as your understanding of the problem changes. Do not treat an eval set as a static, academic-style test set.
Every eval set is different, but there are some common techniques I use for constructing and analyzing them. Nowadays, I always use Claude Code to build a custom frontend app to help me analyze model performance on my eval sets. The frontend app allows me to quickly do two things:
- Find examples the model has errored on
- Tag data to help me organize it
In the next section I'll show a sample eval app and walk through how I conduct error analysis.
Error Analysis
Below is an example error analysis on the RealworldQA dataset. In this dataset, each image comes with a multiple choice question and an answer:

How many cars are moving?
A. 2
B. 1
C. 0
Please answer directly with only the letter of the correct option and nothing else.
For each example you have a ground truth (C), a prediction (one of A, B, or C), and a set of tags for that image such as cars, street view, or nighttime.
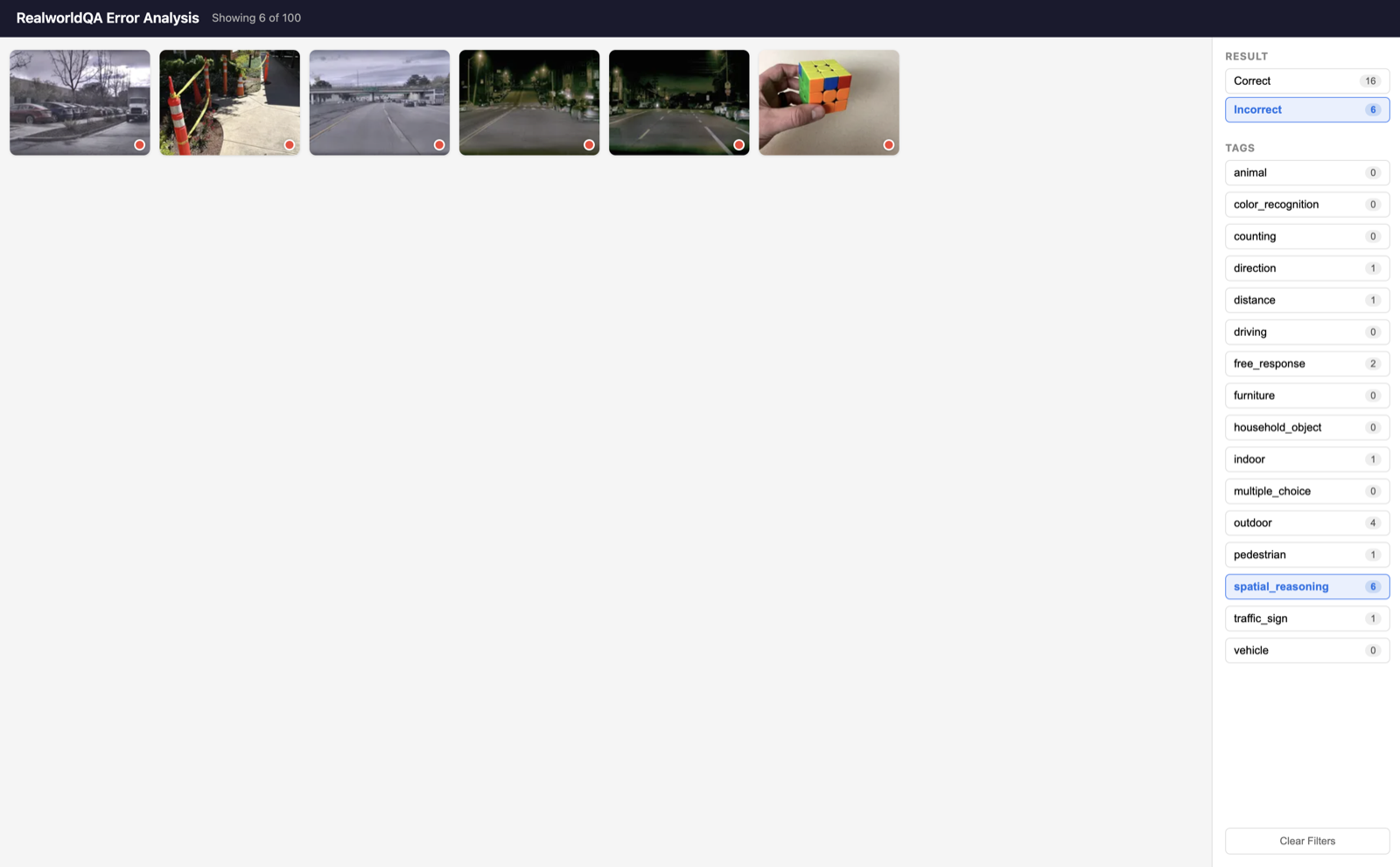
The main page should let you view many examples at once so you can quickly find problem areas to focus on. A couple things to highlight on the main page below:
- Each image has a green or red circle in the bottom right corner indicating whether the model made a correct or incorrect prediction, so you can quickly spot trends amongst correct and incorrect examples.
- On the right side, you can see different filters, such as filtering by correct/incorrect or by tag.

Below is an example of applying a few filters. You can quickly find incorrect examples and then use the tags to see what your largest error categories are. In the example below I've filtered by Incorrect and spatial_reasoning.
I can then click into a specific example to see the question, ground truth, and prediction in order to further investigate the error.
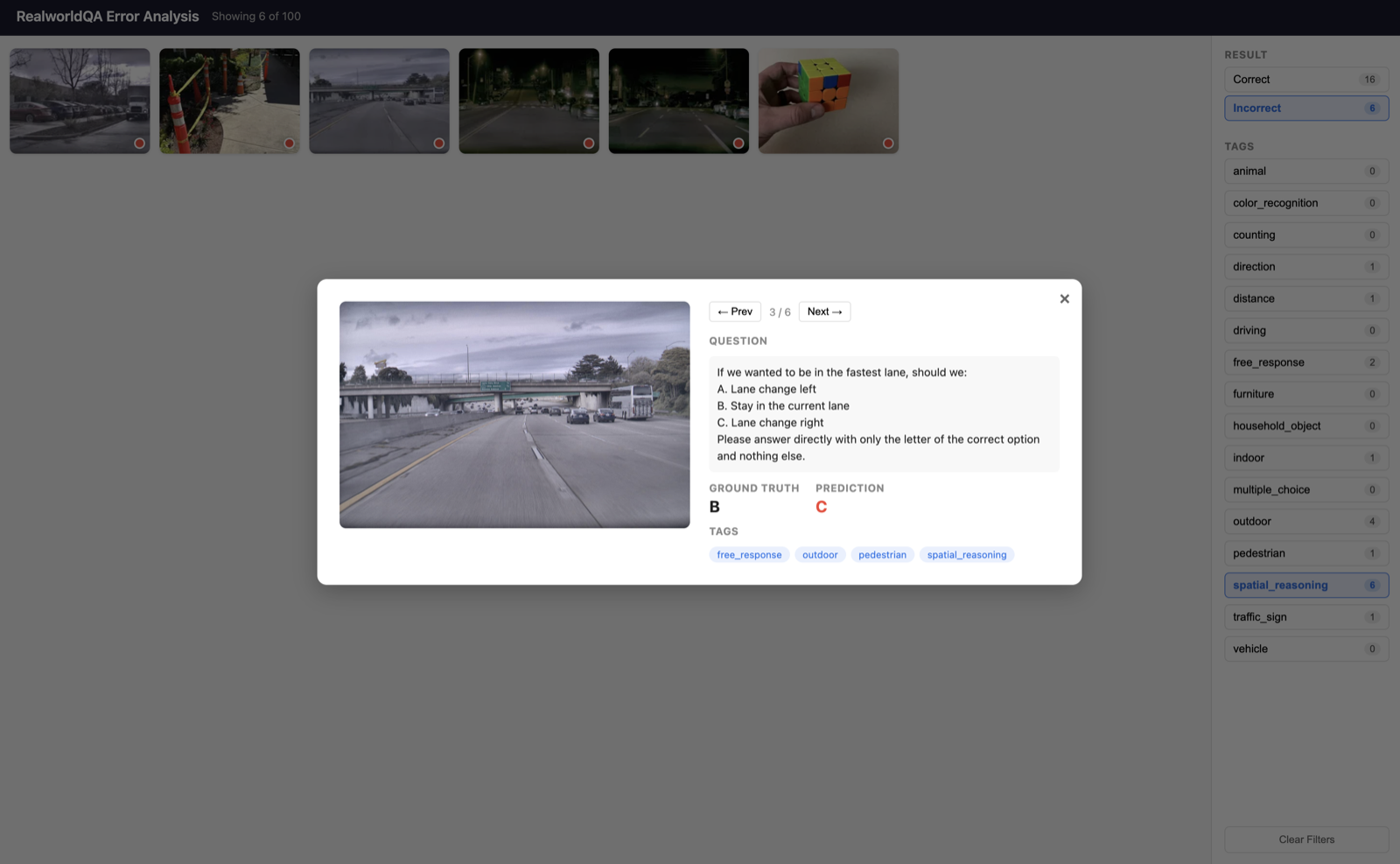
This workflow lets me quickly identify problems to work on simply by filtering to incorrect examples and viewing the tags. It also helps me prioritize: after filtering by Incorrect, the tags with the highest incorrect count are usually the ones to focus on first. I consider this workflow a modern update to the Excel spreadsheet error analysis workflow described in Machine Learning Yearning.
Two Types of Experiments
Once error analysis has surfaced a problem, we need to fix it. To illustrate how I approach this, I'll walk through an example from a project I recently worked on.
I was fine-tuning a VLM (vision-language model) for document parsing. Specifically, I was taking an existing pre-trained VLM and fine-tuning it on a dataset of internal documents. Through error analysis on my eval sets, I found that the model was having trouble transcribing certain rare words, such as medical terminology. For example, it would transcribe the following text:
Within the endomembrane system, nascent polypeptides translocate into the cisternae of the rough endoplasmic reticulum
As:
Within the endmembrene system, nascnt polypeptodes translocate into the sisterna of the rough endoplasmic reticolumn
I had a clear symptom, but not enough information to form a hypothesis about why the model was failing. So my first experiment wasn't a fix. It was an attempt to gather more information.
Gathering Information I ran the base model (the un-fine-tuned model) on the same eval set and compared the results. This showed that the fine-tuned model had better overall performance than the base model.
| model | eval performance |
|---|---|
| base | 85% |
| fine-tuned | 89% |
To dig deeper, I collected a set of examples containing these rare words and re-ran the experiment on just that set.
| model | rare-word eval performance |
|---|---|
| base | 92% |
| fine-tuned | 88% |
This showed clear catastrophic forgetting: the base model outperformed the fine-tuned model on rare words, meaning the fine-tuning process had caused the model to "forget" knowledge it previously had. Now that I had a diagnosis, I could come up with a hypothesis that directly targeted the underlying problem.
Testing a Hypothesis To combat catastrophic forgetting, there were several approaches I could take, including adding regularization or improving the input data mixture with examples of the words in question. Because I had a small training dataset, I decided to go with LoRA (Low-Rank Adaptation), which decreases the number of tunable parameters and helps avoid overfitting. This resulted in an improvement in rare-word eval performance with no drop in overall eval performance:
| model | rare-word eval performance |
|---|---|
| base | 92% |
| fine-tuned | 93% |
Looking back, this project illustrates a pattern I see in almost every ML problem: there are really two types of experiments. The first is information gathering: when you don't have enough context to form a hypothesis, you run an experiment just to learn something. The second is hypothesis testing: when you already know what you think is wrong and have a candidate fix, you run an experiment to validate it. I almost always run information-gathering experiments first, because it's tempting to jump straight to fixes, but without a good understanding of the problem you end up blindly trying things without getting good results. If I had skipped the diagnosis on this project, I might have spent weeks collecting more medical documents or tuning hyperparameters, when the actual fix (LoRA) only made sense once I understood that the problem was catastrophic forgetting.
Data-Centric AI
Data-centric AI refers to a particularly important class of type 2 experiments: fixing issues by modifying the underlying training data rather than the model itself. The way I've come to think about it is that the training data is a hyperparameter (arguably the most important one), and should be iterated on just like any other hyperparameter. In my experience, data-centric changes are both the most common and most successful type 2 experiments, and also the most overlooked.
This methodology was particularly useful to me in the early days of LandingAI. For some background, I was originally working on vision solutions for manufacturers. On a manufacturing line, you'll have all your regular steps to build the product, and at the end of the line you'll have a quality assurance step where the product is inspected for any defects such as scratches or incorrectly assembled parts. I would help the manufacturer build a system that used machine learning models to automate this step.
I initially approached this problem by having the quality assurance team help me label the data (since they knew best what was a defect and what wasn't), and I focused on the modeling side. But I quickly found that no matter how much I iterated on the model, I couldn't improve performance to a satisfactory level. In my investigations, I started to notice some inconsistencies in the labels.
One thing that makes building machine learning solutions for manufacturing difficult is the lack of defective data. The manufacturer is intentionally trying NOT to produce defective products, so you always have a shortage of examples to train the model on. The other problem, which is what I uncovered, is that there are actually a lot of inconsistencies around what is and is not a defect. Clearly defective products are obviously defective, but most defects land in a gray zone where they could go either way.
To take an example from Andrew Ng's Tips for the Data-Centric AI Future, where he is classifying scratches on pills:

You can see that some very small scratches are labeled defective while some larger scratches are labeled okay. When you have a small data cohort combined with an ambiguous labeling scheme, this is by far the biggest contributor to low model performance. Simply coming up with consistent labeling rules can dramatically improve your performance:

You might be wondering, "But what does this have to do with my problem? I train on millions of examples, not small datasets." This is generally true, but there are almost always smaller cohorts of data within your training set that contain inconsistencies. If these smaller cohorts matter to you, the errors will show up in your eval sets.
There are also many data-centric techniques that aren't related to small data or inconsistent labeling. Just take a look at any modern LLM paper, such as the Qwen3-VL Technical Report or 2 OLMo 2 Furious, and you'll see that most of the paper is dedicated to describing the data. They cover a range of techniques such as how to balance training data from different sources, how to clean and filter the data, and how to curate synthetic data.
To bring this back to the framing at the top of the section: treat your training data like a hyperparameter. Most teams I've worked with will iterate dozens of times on learning rates, batch sizes, and model architectures, but only iterate once or twice on the underlying training data. That ratio is backwards. Every change to the data (adding examples, removing examples, relabeling, filtering, rebalancing) is an experiment, and it should be tracked on your eval sets the same way any other experiment would be. In my experience, this is the single highest-leverage shift most ML projects can make.
Machine Learning in the Modern Era of AI
This has largely been my machine learning workflow for the last 10 years, with the exception of using Claude Code to build the error analysis app, which I started doing in the last few years. AI is rapidly changing the day-to-day of an ML engineer, and I expect the specific tools I reach for will keep shifting. But I think this makes the fundamentals in this post more important, not less. Eval sets, error analysis, and disciplined data iteration are exactly the levers you use to steer an AI coding assistant or research agent toward the right problem. If you don't have a strong grip on these fundamentals yourself, you can't meaningfully direct an AI system that does.
Later this year I plan to circle back with a follow-up post on how I've been integrating AI into this workflow. Think of it as a continuation of the ideas here, not a replacement.